たくさんの機能があるAmazonサーバ。ユーザがダウンロードするファイルは、容量うんぬんというよりはマナー的にzip化したいところです。残念ながら「S3」の機能ではサポートされていないようです。弊方では以下を試しました。
その1:Lambdaから「zipコマンド」を呼出す
まずはUNIXコマンドを使用した方が、処理も早くて信頼性がありそうです。しかし、Lambdaからzipを呼び出したしましたが、lambdaテスト画面で、コマンドなし エラーになりました。
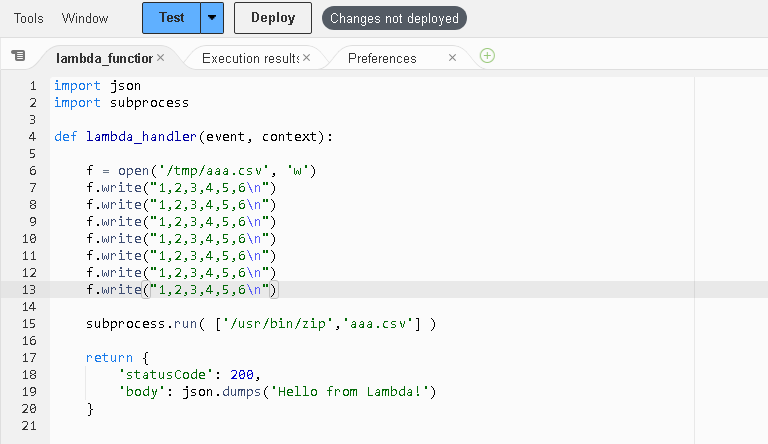
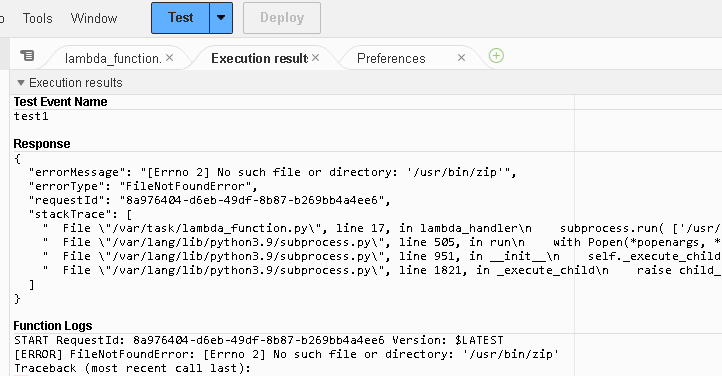
“ls”はたたけるようなので、/usr/binをリストしてみると、基本コマンドしか配置されてないようです。「CloudShell」(何用?)や「EC2」(仮想サーバ)では、zipはつかえるのですけどね。残念。
その2:Lambdaでpythonの「Zipfile」を使用する
以下のように「S3」から/tmpにコピーして、python上でzip化し、「S3」に戻すようにしてみました。
import boto3
import zipfile
def lambda_handler(event, context):
:
中 略
:
csv_fname = "対象ファイル名"
zipname = csv_fname + ".zip"
s3res = boto3.resource('s3')
myBucket = s3res.Bucket("S3バケット名")
myBucket.download_file(csv_fname, "/tmp/" + csv_fname)
with zipfile.ZipFile("/tmp/" + zipname, 'w',
compression=zipfile.ZIP_DEFLATED) as zf:
zf.write("/tmp/" + csv_fname, csv_fname)
myBucket.upload_file("/tmp/" + zipname, zipname)
os.remove( "/tmp/" + csv_fname)
os.remove( "/tmp/" + zipname)
s3clt.delete_object( Bucket=MY_BUCKET, Key=csv_fname )
これで速度、信頼性もそこそこ問題ないようです。むろん本番用では、各fileの実在checkと、try – except を入れます。Lambdaのストレージサイズも必要サイズにUPしておきます。