AWSのサーバ内部プログラムであるLambda。WEBページを構築する場合、通常は以下の手順となります。
- ブラウザから、Lambda関数に割当てられたAWS Gateway のURLを呼出し。
- そのLambda内でDynamoDBにアクセス。
- Lambda内で、HTTPレスポンスを編集し返却。
- プラウザ側でそのレスポンスを受信。
AWS Gatewayを呼び出すには、以下のようにJavascriptのfetch()を使います。(CGIとしてcallも可能でしたがブラウザから警告がでました。)
var myHeaders = new Headers();
myHeaders.append("Content-Type", "application/json");
var raw = JSON.stringify( {
"パラメタ名" : パラメタ値,
中 略
} );
var requestOptions = {
method: 'POST',
headers: myHeaders,
body: raw,
redirect: 'follow'
};
fetch( "https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/dev", requestOptions )
.then( response => response.text() )
.then( result => procResponce( result ) )
.catch( error => fetch_error( error ) );
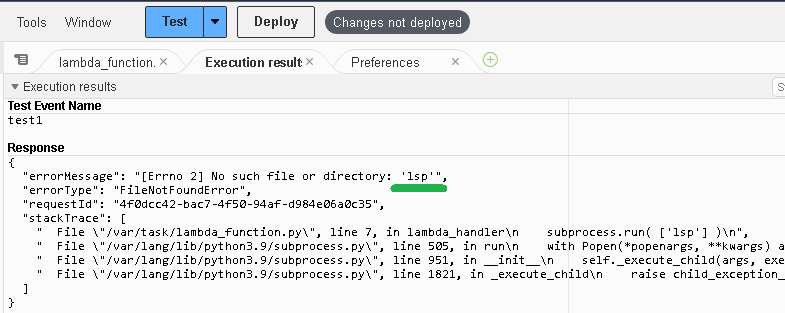
fetchのエラーを、fetch_error()関数でキャッチしているのですが、たまに”TypeError: Failed to fetch”が出ます。
うまく呼べるときは呼べるのですが、割とサーバへリクエストする間隔が短いとき発生する感じです。Lambda関数が何処まで実行されているかは、普通の作込みではわかりません。HTTPレスポンス(procResponce()の関数の呼出し)が得られていないで、途中で停止したのでしょうか?
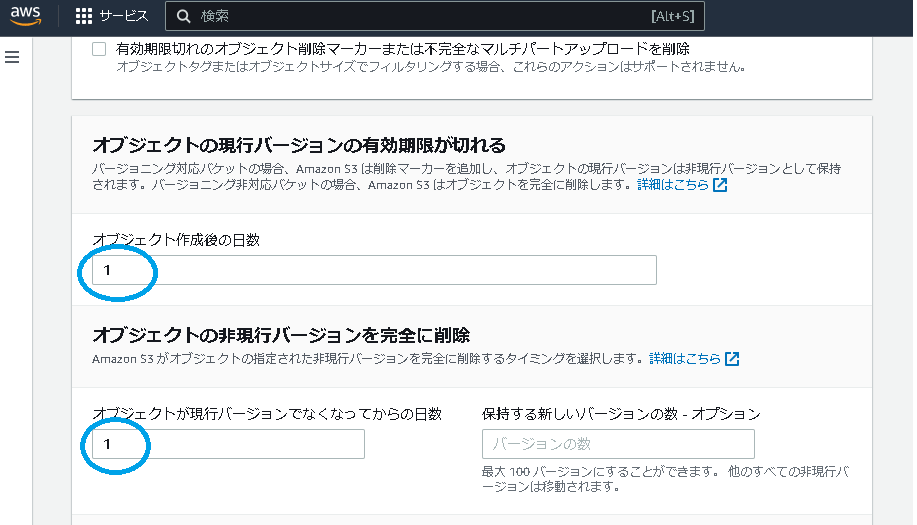
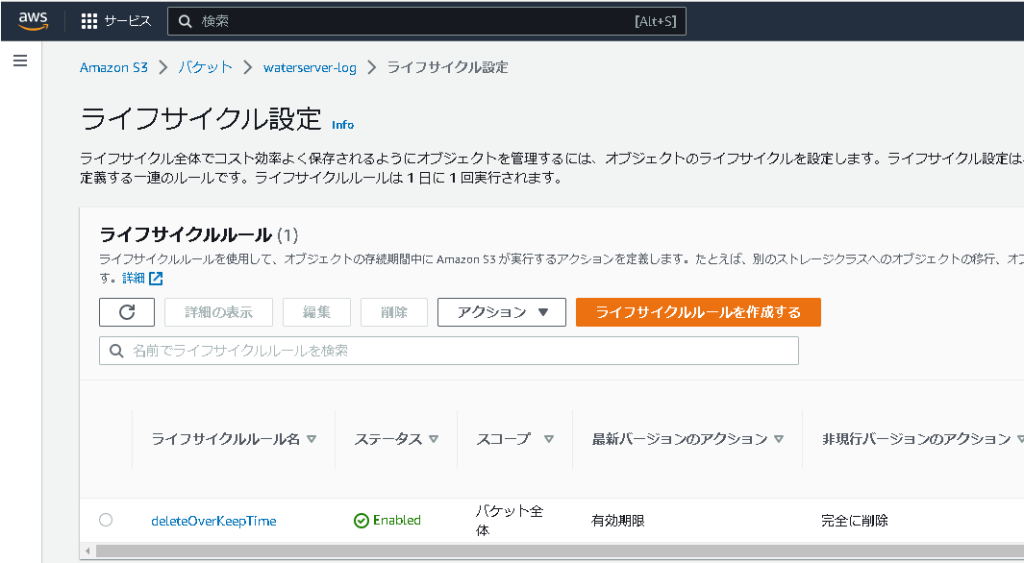
原因は簡単でした。Lambda関数のメモリ容量が少なすぎました。デフォルト128MBはいくら何でも小さすぎます。調整箇所は下図です。
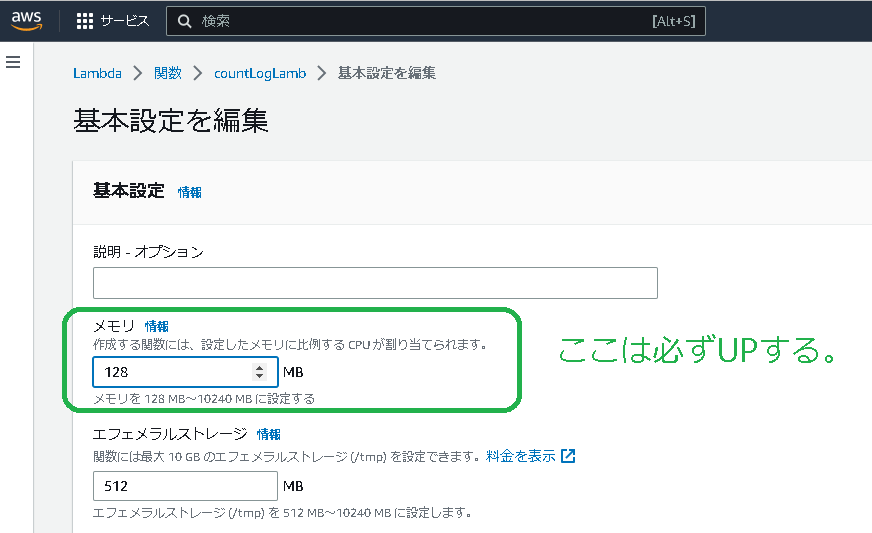
Lambda関数のタイムアウト値は下図のように直ぐエラーがでるので気付きやいすですが、メモリ使用量(しかもまさかの小容量)は気付きにくいです。

弊方は2048までUP。これでレスポンスも含め、すごく調子よくなりました。Lambda関数生成時に、指定項目になってくれるとGoodですね。