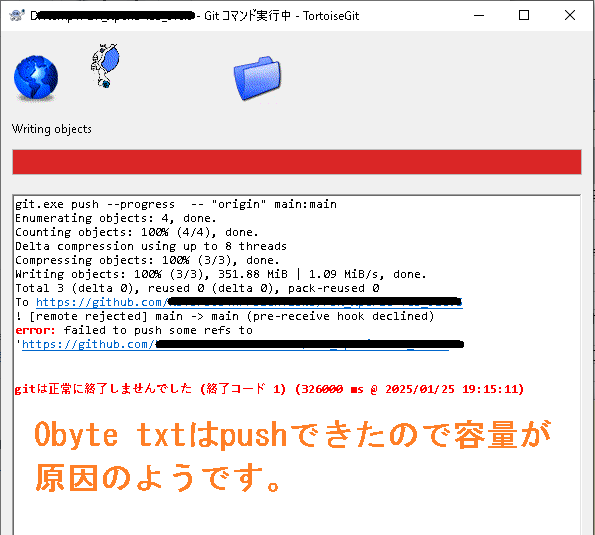
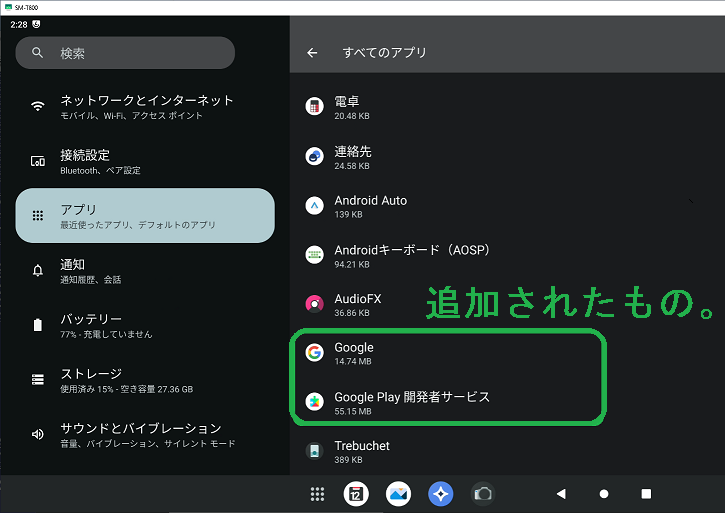
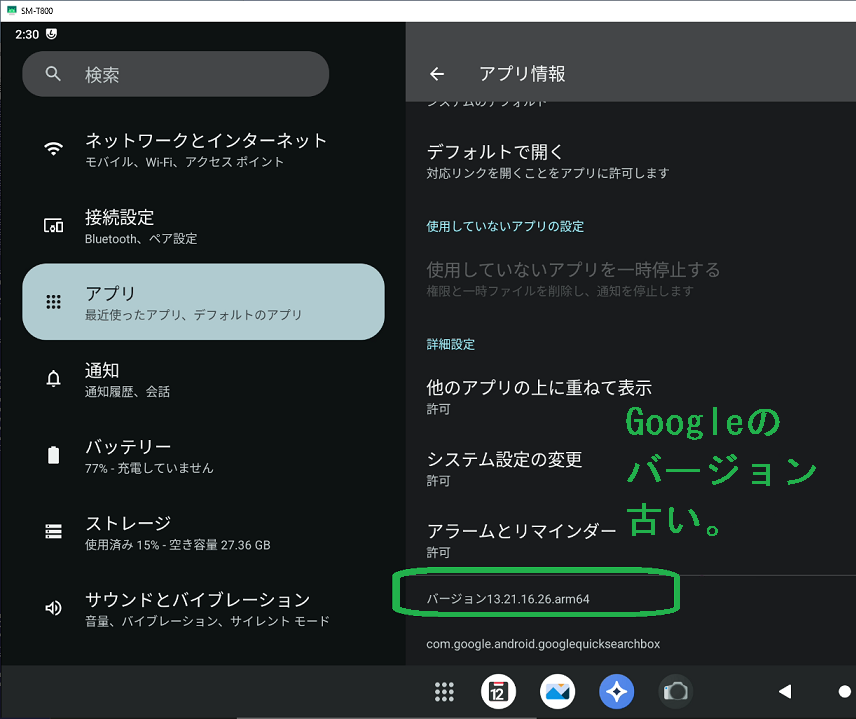
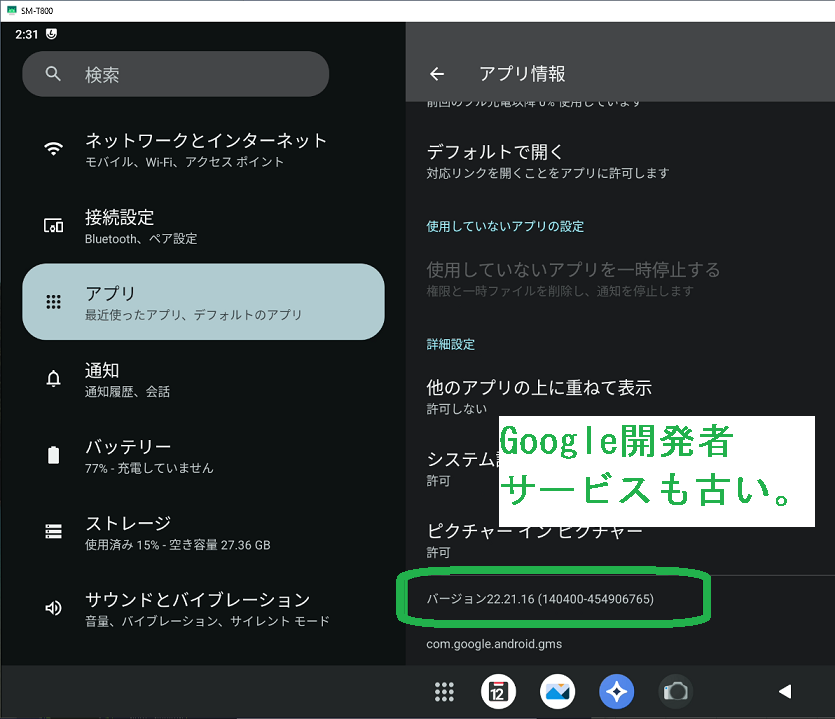
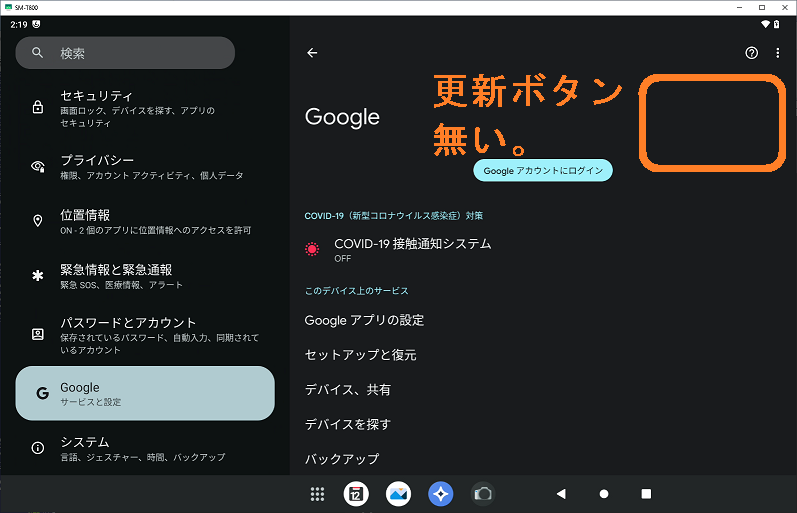
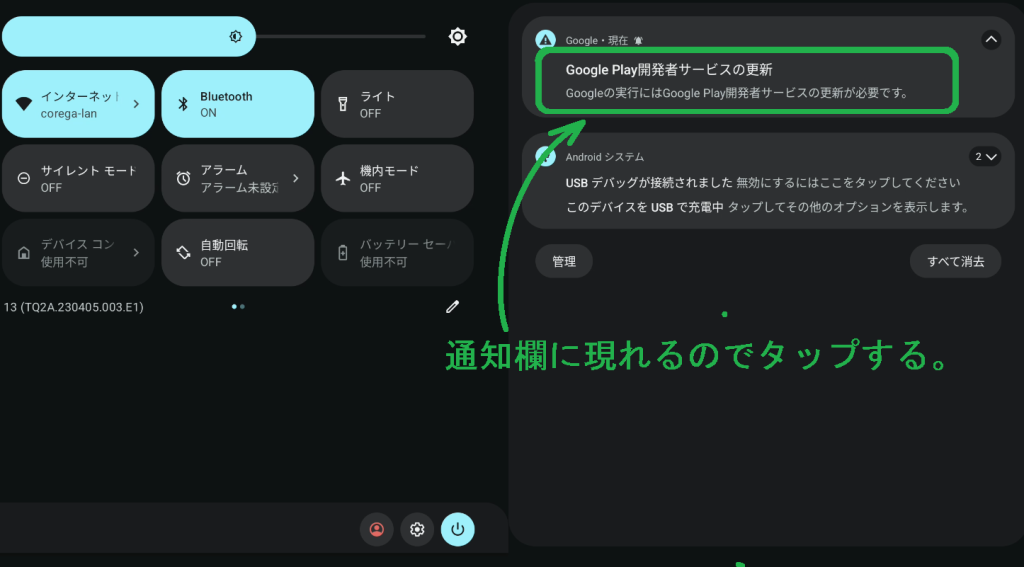
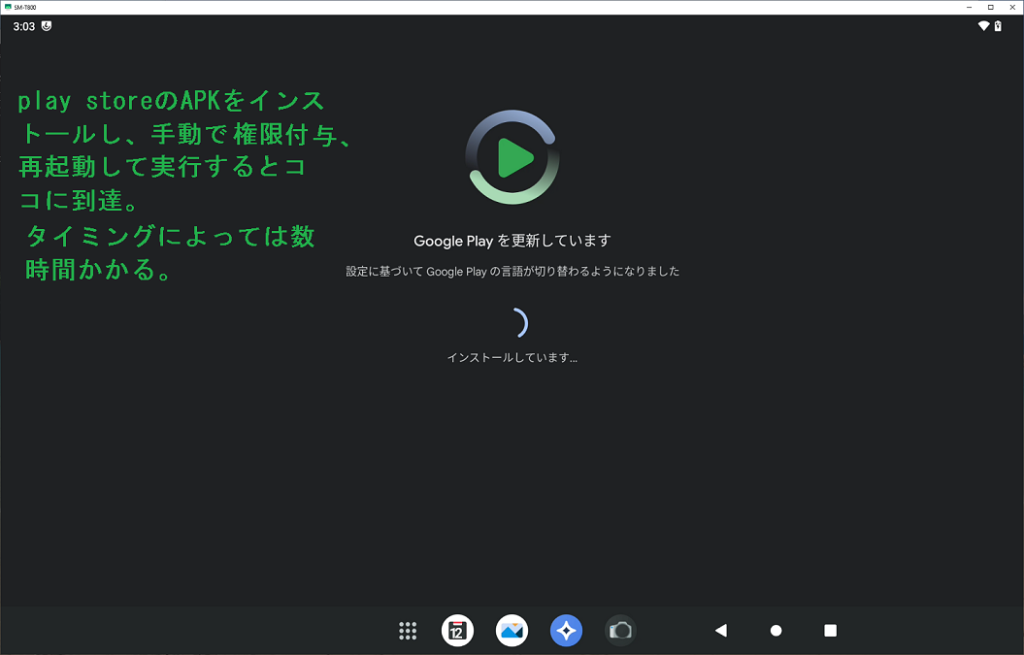
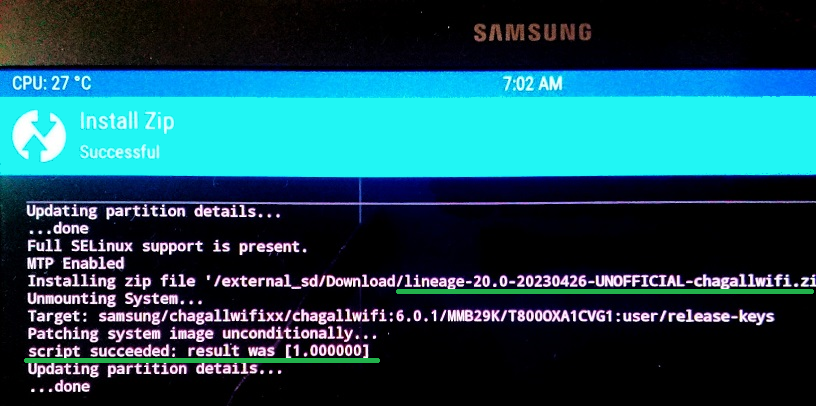
前回では、SM-T800 を Android13 相当にUpdateまでしました。 次にカスタムOS用のGoogleサービスエンジンの一つである MindTheGapps のインストールエラーの調査と対策を行います。
別バージョンを試す
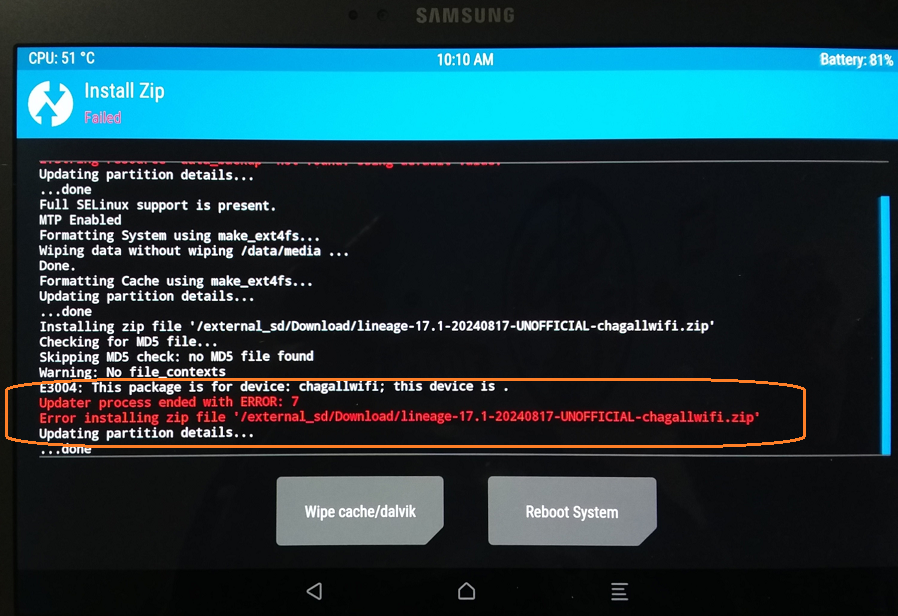
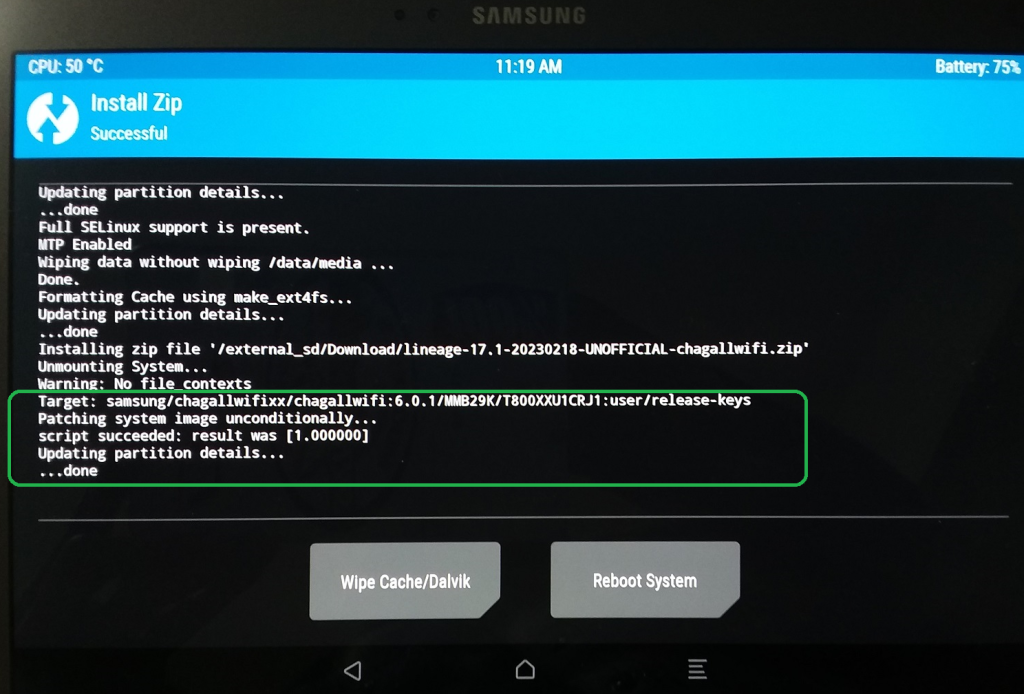
XDAのSM-T800 LinageOS 20 のページをみると、MindTheGapps13 がインストールできないとの投稿があり、その対策版情報がありました。MindTheGapps_Legacy-13.0.0-arm64-20231025_200931.zip です。試したところ、前回の「Could not mount .. Googleサービス
別種Gappを試す
MindTheGapps でなく、別種Gapp: NikGapp というのがあります。こちらを試しましたがダメでした。
NikGapps-core-arm64-13-20241231-signed.zip TWRPで Error 1 発生。 NikGapps-core-arm64-12-20241231-signed.zip TWRPで Error 1 発生。 NikGapps-Juan-Basic-arm64-13-20250110-unofficial.zip TWRPで Error 1 発生。
MindTheGapp中身を調べる
MindTheGapps のパッケージはただのzipなので構造と仕組みを調べてみます。
おおざっぱdirectory構造は以下のとおりです。黒字がDirectory、緑字がfile です。
META-INF
com
android
google
android
update-binary [① ]
system [②ココがインストール配布物、OSのDirectory構造と同じ ]
addon.d
product
app
lib
各.so (unix共有dynamic Library)
lib64
各.so (unix共有dynamic Library)
priv-app
system_ext
上記①は、UNIXシェルスクリプト です。幸い割と得意なので解析&デバックできそうです。
Update-binaryの中身
update-binary
OS Directory ( /system , /product , /system_ext ) を一旦unmoutする。
端末ストレージの/devリスト:/etc/recovery.fstab
/devファイル から、/system, /product, /system_ext を 再mount する。
ストレージ残容量をチェックする。
インストール対象の 各アプリ.apk の一覧を 30-gapps.sh /system/android.d
MindTheGapps/system 下の全fileを、パーミッションを保ったまま、OSの/systemにコピーする。OSの/product が /system と別ストレージの場合、MindTheGapps/system/produc を パーミッションを保ったまま、OSの/product にコピーする。
OSの/system_ext が /system と別ストレージの場合、MindTheGapps/system/system_ext を パーミッションを保ったまま、OSの/system_ext にコピーする。
Update-binaryの修正 1
update-binary echo update-binary ui_print() を使います。MindTheGapps のzipを解凍し、update-binary 7zip
folder全体zipしていまうと Directory 階層が出来てしまうので、TWRPがzipを認識しなくなります
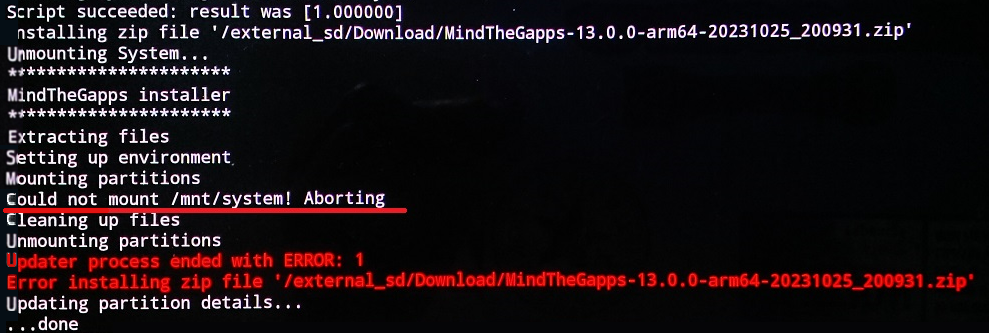
実行してみると以下のような結果でした。
前述のスクリプト手順2. が 端末 もしくは TWRP に合っていないようです。SM-T800の/etc/recovery.fstab の内容は以下のとおりです。
/boot emmc /dev/block/bootdevice/by-name/BOOT /recovery emmc /dev/block/bootdevice/by-name/RECOVERY flags=backup= 1 /misc emmc /dev/block/platform/dw_mmc.0/by-name/OTA /system ext4 /dev/block/bootdevice/by-name/SYSTEM /system_image emmc /dev/block/bootdevice/by-name/SYSTEM /data ext4 /dev/block/bootdevice/by-name/USERDATA flags=encryptable=footer ; length = -16384 /cache ext4 /dev/block/bootdevice/by-name/CACHE /modem emmc /dev/block/bootdevice/by-name/RADIO flags=backup= 1 ; display = "Modem" ; flashimg /hidden ext4 /dev/block/bootdevice/by-name/HIDDEN flags=backup= 1 ; display = "Hidden" /hidden_image emmc /dev/block/bootdevice/by-name/HIDDEN flags=display="Hidden Image" ; flashimg /efs ext4 /dev/block/bootdevice/by-name/EFS flags=backup= 1 ; display = "EFS" /efs1 emmc /dev/block/bootdevice/by-name/m9kefs1 flags=backup= 1 ; subpartitionof = /efs /efs2 emmc /dev/block/bootdevice/by-name/m9kefs2 flags=backup= 1 ; subpartitionof = /efs /efs3 emmc /dev/block/bootdevice/by-name/m9kefs3 flags=backup= 1 ; subpartitionof = /efs /external_sd vfat /dev/block/mmcblk1p1 /dev/block/mmcblk1 flags=display="Micro SDCard" ; storage ; wipeingui ; removable /usb-otg vfat /dev/block/sda1 /dev/block/sda flags=display="USB OTG" ; storage ; wipeingui ; removable
上記「 /system ext4 /dev/block/bootdevice/by-name/SYSTEM 」行の「/dev/block/bootdevice/by-name/SYSTEM 」が抽出できればよいようです。このオリジナルの抽出コード行は以下のようになっています。
grep -v "^#" /etc/recovery.fstab | grep "[[:blank:]] $1 [[:blank:]]" | tail -n1 | tr -s [:blank:] ' ' | cut -d ' ' -f1
コメントでなく、$1(system)が見つかった 最初の一行をスペースでカットした… みたいな感じですね。SM-T800のフォーマットと合っていないのでしょう。MindTheGapps_Legacy-13.0.0-arm64-20231025_200931.zip の抽出コード行は以下のように少しシンプルですが、grep の -o オプションはUNIX処理系によって無いようです。オリジナルgrepには無し。TWRP3.7上では使えませんでした。
cat /etc/recovery.fstab | cut -d '#' -f 1 | grep /system | grep -o '/dev/[^ ]*' | head -1
いずれにしても修正が必要です。 弊方ではawk ps -ef|grep プロセス名|awk `{print $1}` と千回は叩いたでしょうか。 TWRP上でも使えました。 頭コメント^#判定も特に不要。 以下コード例です。これで一つ解決です。
cat /etc/recovery.fstab | grep ^ $1 | awk '{print $3}' | head -1
Update-binaryの修正2
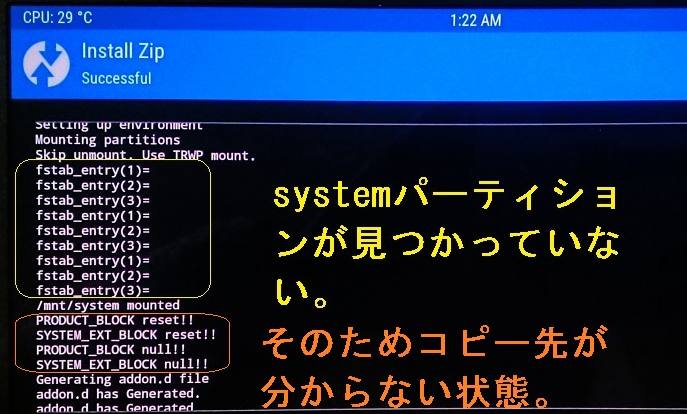
前述修正1では、/devファイルは取得できるようになりましたが、インストール後の反応は未だ見られません。以下のように調べます。
update-binary MindTheGapps.zip をinstall。
MindTheGapps の作業フォルダ /tmp/system に移動。
試したいスクリプトと同じコマンドを叩く。
これにより問題のあった行は以下でした。
ui_print "Copying files" cp --preserve=a -r ./ * "${ SYSTEM_OUT }/"
cp コマンドの –preserve オプションはUNIX処理系によって無いようです。TWRP3.7ではオプションエラーになりました。 cp $? -r
ui_print "Copying files" cp -pr ./ * "${ SYSTEM_OUT }/"
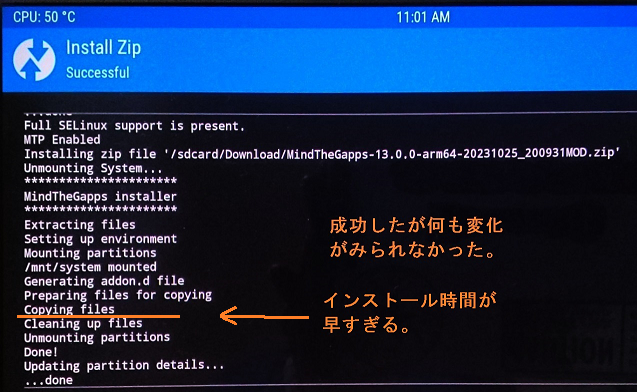
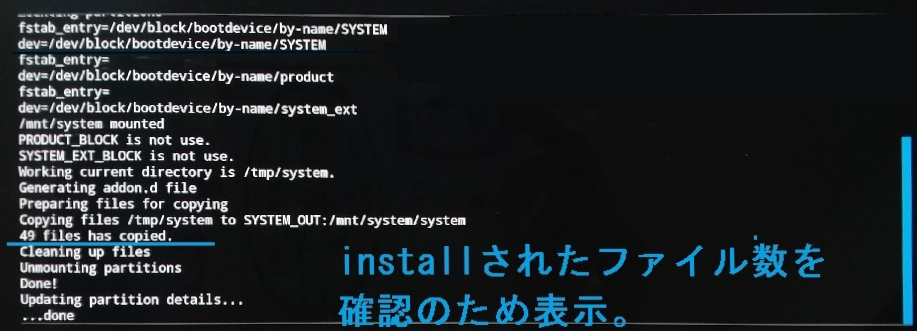
これでインストール内容は反映されるようになりました。しかしこれでだけではインストールコピー失敗の気付きになりません。以下のようにコピーされたfile数を表示できるようにします。
ls -1R ${ SYSTEM_OUT } > $TMP //MindGappCpBefore.txt cp -pr ./ * "${ SYSTEM_OUT }/" ls -1R ${ SYSTEM_OUT } > $TMP /MindGappCpAfter.txt # show number of copy files. diff -w /tmp/MindGappCpBefore.txt /tmp/MindGappCpAfter.txt | grep ^+[a-zA-Z ]> $TMP /MindGappCpList.txt rm -f $TMP //MindGappCpBefore.txt $TMP /MindGappCpAfter.txt COPY_COUNT = ` cat $TMP /MindGappCpList.txt | wc -l ` ui_print " $COPY_COUNT files has copied."
Update-binaryの実行結果
修正後のトータル実行結果は以下のとおり。他の端末ではテストできていないので SM-T800 用と明記しておきます。
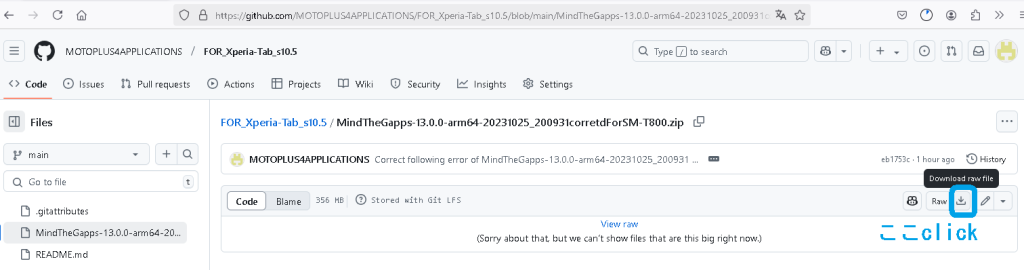
修正した MindTheGapps-13.0.0-arm64*.zip は機種依存であるとまずいので、本流にマージせず個別にGit-Hubに公開しました。 ここから MindTheGapps-13.0.0-arm64*.zip を選んで以下のようにDownloadしてください。
これで Googleサービス 次のサービスのセットアップに続きます 。